我发现了使用 ChatGPT(成功地)进行 Web 抓取的漏洞。这是它的工作原理


I Found a Loophole to (Successfully) Web Scrape Using ChatGPT. Here’s How it Works
Scrape any website with ChatGPT using this approach (demo with Amazon and Twitter)
进行 Web 抓取的漏洞。这是它的工作原理插图")
In a previous article, I made a demo on how to scrape websites by writing simple prompts for ChatGPT like “scrape website X using Python.”
But that doesn’t always work.
Actually, after trying to scrape dozens of websites using ChatGPT, I came to the conclusion that plain prompts like the one before almost never work when it comes to web scraping.
But I found another approach that will help us scrape any website out there using ChatGPT and some basic HTML.
First Things First — Use The Advanced Version of ChatGPT (Playground)
To quickly scrape websites using ChatGPT, we need to use the advanced version of ChatGPT — Playground. This version has fewer restrictions and is way faster when it comes to generating code.
Here’s how it looks.
进行 Web 抓取的漏洞。这是它的工作原理插图1")
As you can see, this is different from the classic view of ChatGPT where you can only type a prompt. On Playground, you have more customization options, and, when it comes to generating code, it’s way faster than the basic version.
No more restrictions or slow responses.
For this tutorial, we’ll write our prompts in the box below the “Playground” title.
How to Scrape Any Websites with ChatGPT
To easily explain to you how we’re going to use ChatGPT to scrape any website we want, we’ll start with a simple website called subslikescript that has a list of movies listed on its site.
Later, in this guide, I’ll show you how to use the same approach to scrape sites such as Amazon and Twitter, but let’s keep it simple for now.
If we try a basic prompt like “scrape the movie titles on this website: https://subslikescript.com/movies” it won’t scrape anything. Here’s when we need some HTML knowledge to build the right prompt for ChatGPT.
进行 Web 抓取的漏洞。这是它的工作原理插图2")
Say we want to scrape the movie titles listed in the image above. First, we need to inspect the website. To do so, we right-click on any element and select “Inspect.”
Then we’ll see the image below.
进行 Web 抓取的漏洞。这是它的工作原理插图3")
Now we identify the element we want to scrape data from (those in the red box). As you can see, the elements that contain the data have the tag names ul, a and attribute value scripts-list.
Here’s the prompt we’ll use to extract the movie titles listed.
Scrape this website: https://subslikescript.com/movies with Python and Beautiful Soup. Locate the element with tag “ul” and class “scripts-list”. Scrape all the “a” elements inside. Get the text attribute and print it.
进行 Web 抓取的漏洞。这是它的工作原理插图4")
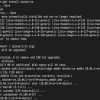
Here’s the code generated.
import requestsfrom bs4 import BeautifulSoup
page = requests.get('https://subslikescript.com/movies/')
soup = BeautifulSoup(page.content, 'html.parser')
scripts_list = soup.find(class_="scripts-list")
all_a_elements = scripts_list.find_all('a')for element in all_a_elements: print(element.get_text())And it successfully extracts all the movie titles!
或测试代码
进行 Web 抓取的漏洞。这是它的工作原理插图5")
Now that you understand the basics let’s scrape Amazon and Twitter.
Scraping Amazon with ChatGPT
Say you want to scrape self-help books from Amazon. First, you have to search “self-help books” on Amazon and copy the link you get.
进行 Web 抓取的漏洞。这是它的工作原理插图6")
Here’s the link I got. The link may vary based on your location. If you want to get the same results as me, use my link.
Now we have to inspect the book titles. Here’s the element we’re going to use.
进行 Web 抓取的漏洞。这是它的工作原理插图7")
If we want to extract the book titles, we need to use the tag name span, class attribute name and a-size-base-plus a-color-base a-text-normal attribute value.
Unlike the previous example, I’m going to use Selenium this time. I’ll add instructions like “wait 5 seconds” and “build an XPath” because those are things we can do with Selenium.
Scrape this website https://www.amazon.com/s?k=self+help+books&sprefix=self+help+%2Caps%2C158&ref=nb_sb_ss_ts-doa-p_2_10 with Python and Selenium.
Wait 5 seconds and locate all the elements with the following xpath: “span” tag, “class” attribute name, and “a-size-base-plus a-color-base a-text-normal” attribute value. Get the text attribute and print them.
进行 Web 抓取的漏洞。这是它的工作原理插图8")
Here’s the code generated (I only had to manually add the path where my chromedriver is located).
from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom time import sleep#initialize webdriverdriver = webdriver.Chrome('<add path of your chromedriver>')#navigate to the websitedriver.get("https://www.amazon.com/s?k=self+help+books&sprefix=self+help+%2Caps%2C158&ref=nb_sb_ss_ts-doa-p_2_10")#wait 5 seconds to let the page loadsleep(5)#locate all the elements with the following xpathelements = driver.find_elements(By.XPATH, '//span[@class="a-size-base-plus a-color-base a-text-normal"]')#get the text attribute of each element and print itfor element in elements: print(element.text)#close the webdriverdriver.close()And it extracts all the book titles from Amazon!
进行 Web 抓取的漏洞。这是它的工作原理插图9")
Scraping Twitter with ChatGPT
Now let’s say you want to scrape all the tweets related to the word “ChatGPT.” First, you have to search “ChatGPT” on Twitter and copy the link you get.
Here’s the link I got. Now we have to inspect any tweet. Here’s the element we’re going to use.
进行 Web 抓取的漏洞。这是它的工作原理插图10")
If we want to extract the tweet, we need to use the div tag, and lang attribute name.
We’re going to use Selenium again.
Scrape this website: https://twitter.com/search?q=chatgpt&src=typed_query using Python, Selenium and chromedriver.
Maximize the window, wait 15 seconds and locate all the elements that have the following XPath: “div” tag, attribute name “lang”. Print the text inside these elements.
进行 Web 抓取的漏洞。这是它的工作原理插图11")
Here’s the code generated (again, I had to add the path where my chromedriver is located)
from selenium import webdriverimport time
driver = webdriver.Chrome("/Users/frankandrade/Downloads/chromedriver")
driver.maximize_window()
driver.get("https://twitter.com/search?q=chatgpt&src=typed_query")
time.sleep(15)
elements = driver.find_elements_by_xpath("//div[@lang]")for element in elements: print(element.text)
driver.quit()If you test it out, you’re going to extract the first 2 or 3 tweets from the search result. To scrape more tweets you have to add “scroll down X times” to the instruction given before.
Congratulations! You learned how to scrape websites without writing code, but letting ChatGPT do all the dirty work.
Turn websites into datasets! Get my FREE Web Scraping Cheat Sheet by joining my email list with 20k+ people.
If you enjoy reading stories like these and want to support me as a writer, consider signing up to become a Medium member. It’s $5 a month, giving you unlimited access to thousands of Python guides and Data science articles. If you sign up using my link, I’ll earn a small commission with no extra cost to you.