傻瓜式文章爬虫-newspaper库简介


今天比较闲,我就浏览了会github上有关python爬虫的项目。看到一个newspaper库,关注数挺高的。作者受lxml的强大和requests的简洁,开发了newspaper库。
requests库的作者都盛赞newspaper库的牛B。
"Newspaper is an amazing python library for extracting & curating articles." -- tweeted by Kenneth Reitz, Author of requests一、newspaper特性
- 多进程文章下载框架
- 新闻链接识别
- 可从html文件中提取文本、图片
- 可文章关键词提取
- 可生成文章概要
- 提取文章作者名
- 谷歌趋势词提取
- 支持十数种语言(含中文)
其实之前我写过一个类似的库的介绍-goose(仅支持python2),跟newspaper有类似功能。 文章名《不会写爬虫的快来goose一下》
二、安装
pip3 install newspaper3k注意:在python3中安装,必须是newspaper3k。 newspaper是python2上的库。
三、开始代码
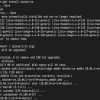
3.1newspaper支持的语言
import newspaperprint(newspaper.languages())
Your available languages are:
input code full name ar Arabic da Danish de German el Greek en English es Spanish fi Finnish fr French he Hebrew hu Hungarian id Indonesian it Italian ko Korean mk Macedonian nb Norwegian (Bokmål) nl Dutch no Norwegian pt Portuguese ru Russian sv Swedish tr Turkish vi Vietnamese zh Chinese3.2 文章内容提取
提取文章内容,如作者、出版日期、文章内容、图片链接
from newspaper import Article
url = 'http://media.china.com.cn/cmyw/2017-06-13/1067887.html'
article = Article(url, language='zh')#下载文章article.download()#查看文章的html数据#print(article.html)#解析文章html数据article.parse()#提取各种数据信息#作者print(article.authors)#出版日期print(article.publish_date)#新闻内容print(article.text)#文章的首图链接print(article.top_image)3.3 自然语言处理
继续3.2部分代码
#nlp初始化article.nlp()#提取关键词print(article.keywords)#文章概要print(article.summary)3.4 更精细的使用方法
上面的方法是默认的方法,如果你确定某网站采用的全部是一种语言,你可以使用下面代码
#文档中使用的案例import newspaper
sina_paper = newspaper.build('http://www.sina.com.cn/', language='zh')for category in sina_paper.category_urls(): print(category)输出了新浪网所有栏目
http://roll.fashion.sina.com.cnhttp://www.sina.com.cn/http://hainan.sina.com.cnhttp://jiangsu.sina.com.cnhttp://vr.sina.cnhttp://cq.auto.sina.com.cnhttp://eladies.sina.com.cnhttp://chuangye.sina.com.cnhttp://gx.sina.com.cnhttp://slide.mil.news.sina.com.cnhttp://hlj.sina.com.cnhttp://history.sina.com.cnhttp://tech.sina.com.cn//nmg.sina.com.cnhttp://shiqu.sina.com.cnhttp://ah.sina.com.cnhttp://slide.news.sina.com.cnhttp://chexian.sina.com总结,用着效果没有requests作者夸的那么棒,可能我找的网站正好是newspaper无法完美处理的网站。
Tips:这篇文章抓的是外国网站-Twitter每日推荐导读