Linux内存 占用较高问题排查


一 查看内存情况
#按 k 查看
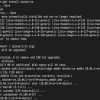
free
#按兆M查看
free -m

- total:总计物理内存的大小。
- used:已使用多大。
- free:可用有多少。
- Shared:多个进程共享的内存总额。
- Buffers/cached:磁盘缓存的大小。
- #所以空闲内存=free+buffers+cached=total-used
内存的使用情况
cat /proc/meminfo
查看进程的内存占用
pidstat -r -p 24427 1 5
内存占用高的前20
ps aux | head -1;ps aux |grep -v PID |sort -rn -k +4 | head -20
动态查看内存占用
slabtop
二 问题定位
cached 占用过高问题
buffer,cached的作用:
cached主要负责缓存文件使用, 日志文件过大造成cached区内存增大把内存占用完 .
Free中的buffer和cache:(它们都是占用内存):
buffer : 作为buffer cache的内存,是块设备(磁盘)的缓冲区,包括读、写磁盘
cache: 作为page cache的内存, 文件系统的cache,包括读、写文件
如果 cache 的值很大,说明cache住的文件数很多。
linux服务器会自动释放内存,保障系统运行,但只会释放够用的内存,而不会去释放更多的内存。
解决方法:
手动释放cached方法有三种(系统默认值是0,释放之后你需要再改回0值):
释放前最好sync一下,防止丢数据
sync 在启动机器或关机之前一定要运行sync命令。记住在任何情况下,慎重地执行sync命令决不会有任何坏处,sync命令强制把磁盘缓冲的所有数据写入磁盘
To free pagecache: #echo 1 > /proc/sys/vm/drop_caches
To free dentries and inodes: #echo 2 > /proc/sys/vm/drop_caches
To free pagecache, dentries and inodes: #echo 3 > /proc/sys/vm/drop_caches
#常用方法是
sync
echo 1 > /proc/sys/vm/drop_caches
#清除后要还原系统默认配置:
echo 0 > /proc/sys/vm/drop_caches#查看设置
sysctl -a | grep drop_caches
补充: echo 字符串 > 文件 就是把字符串内容从定向到文件中

这时查看 free 可以看到 cached 降低了很多
三 linux vm内核参数优化设置
(1)vm.min_free_kbytes
sysctl -a | grep min_free_kbytes #centos6.4默认66M
67584 该文件表示强制Linux VM最低保留多少空闲内存(Kbytes)。

当可用内存低于这个参数时,系统开始回收cache内存,以释放内存,直到可用内存大于这个值。
#改为1g
命令:sysctl -w vm.min_free_kbytes=1048576
(如果命令执行不成功,直接编辑文件进行替换即可)
#查看是否改动
sysctl -a | grep min_free_kbytes
(1)vm.overcommit_memory
执行grep -i commit /proc/meminfo
看到CommitLimit和Committed_As参数。
CommitLimit是一个内存分配上限,CommitLimit = 物理内存 * overcommit_ratio(默认50,即50%) + swap大小
Committed_As是已经分配的内存大小。
--------
vm.overcommit_memory文件指定了内核针对内存分配的策略,其值可以是0、1、2
0: (默认)表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。0 即是启发式的overcommitting handle,会尽量减少swap的使用,root可以分配比一般用户略多的内存
1: 表示内核允许分配所有的物理内存,而不管当前的内存状态如何,允许超过CommitLimit,直至内存用完为止。在数据库服务器上不建议设置为1,从而尽量避免使用swap.
2: 表示不允许超过CommitLimit值
(2)vm.overcommit_ratio
默认值为:50 (即50%)
这个参数值只有在vm.overcommit_memory=2的情况下,这个参数才会生效。
------------------------------------------------------------------------------
vm.vfs_cache_pressure
该项表示内核回收用于directory和inode cache内存的倾向:
缺省值100表示内核将根据pagecache和swapcache,把directory和inode cache保持在一个合理的百分比
降低该值低于100,将导致内核倾向于保留directory和inode cache
增加该值超过100,将导致内核倾向于回收directory和inode cache。
网上文章建议 执行命令:
sysctl -a | grep vfs_cache_pressure
sysctl -w vm.vfs_cache_pressure=200
其实一般情况下不需要调整,只有在极端场景下才建议进行调整,只有此时,才有必要进行调优,这也是调优的意义所在。
vm.dirty_background_ratio 默认为10
所有全局系统进程的脏页数量达到系统总内存的多大比例后,就会触发pdflush/flush/kdmflush等后台回写进程运行。
将vm.dirty_background_ratio设置为5-10,将vm.dirty_ratio设置为它的两倍左右,以确保能持续将脏数据刷新到磁盘,避免瞬间I/O写,产生严重等待(和MySQL中的innodb_max_dirty_pages_pct类似)
vm.dirty_ratio 默认为20
单个进程的脏页数量达到系统总内存的多大比例后,就会触发pdflush/flush/kdmflush等后台回写进程运行。
--------------------------------------------------
vm.panic_on_oom 默认为0开启 为1时表示关闭此功能
等于0时,表示当内存耗尽时,内核会触发OOM killer杀掉最耗内存的进程。
当OOM Killer被启动时,通过观察进程自动计算得出各当前进程的得分 /proc/<PID>/oom_score,分值越高越容易被kill掉。
而且计算分值时主要参照 /proc/<PID>/oom_adj , oom_adj 取值范围从-17到15,当等于-17时表示在任何时候此进程都不会被 oom killer kill掉(适用于mysql)。
/proc/[pid]/oom_adj ,该pid进程被oom killer杀掉的权重,介于 [-17,15]之间,越高的权重,意味着更可能被oom killer选中,-17表示禁止被kill掉。
/proc/[pid]/oom_score,当前该pid进程的被kill的分数,越高的分数意味着越可能被kill,这个数值是根据oom_adj运算后的结果,是oom_killer的主要参考。
sysctl 下有2个可配置选项:
vm.panic_on_oom = 0 #内存不够时内核是否直接panic
vm.oom_kill_allocating_task = 1 #oom-killer是否选择当前正在申请内存的进程进行kill